Pinscrapy
Sep 7, 2017 00:00 · 1506 words · 8 minutes read
For a while now I’ve been meaning to program a content recommender similar to the one described in this post by Dr. Bunsen. The idea is to parse the bookmarks of a Pinboard user and then use machine learning to recommend interesting content based on the bookmarks of other “similar” users.
This post focuses on the first step, i.e. creating the data that will be fed to the machine learning algorithm by crawling a small part of Pinboard. To do that I used Scrapy, a very powerful Python-based application framework for writing web spiders.
Crawling
In order to program the Scrapy spider, one needs to understand how the bookmarks are stored and presented.
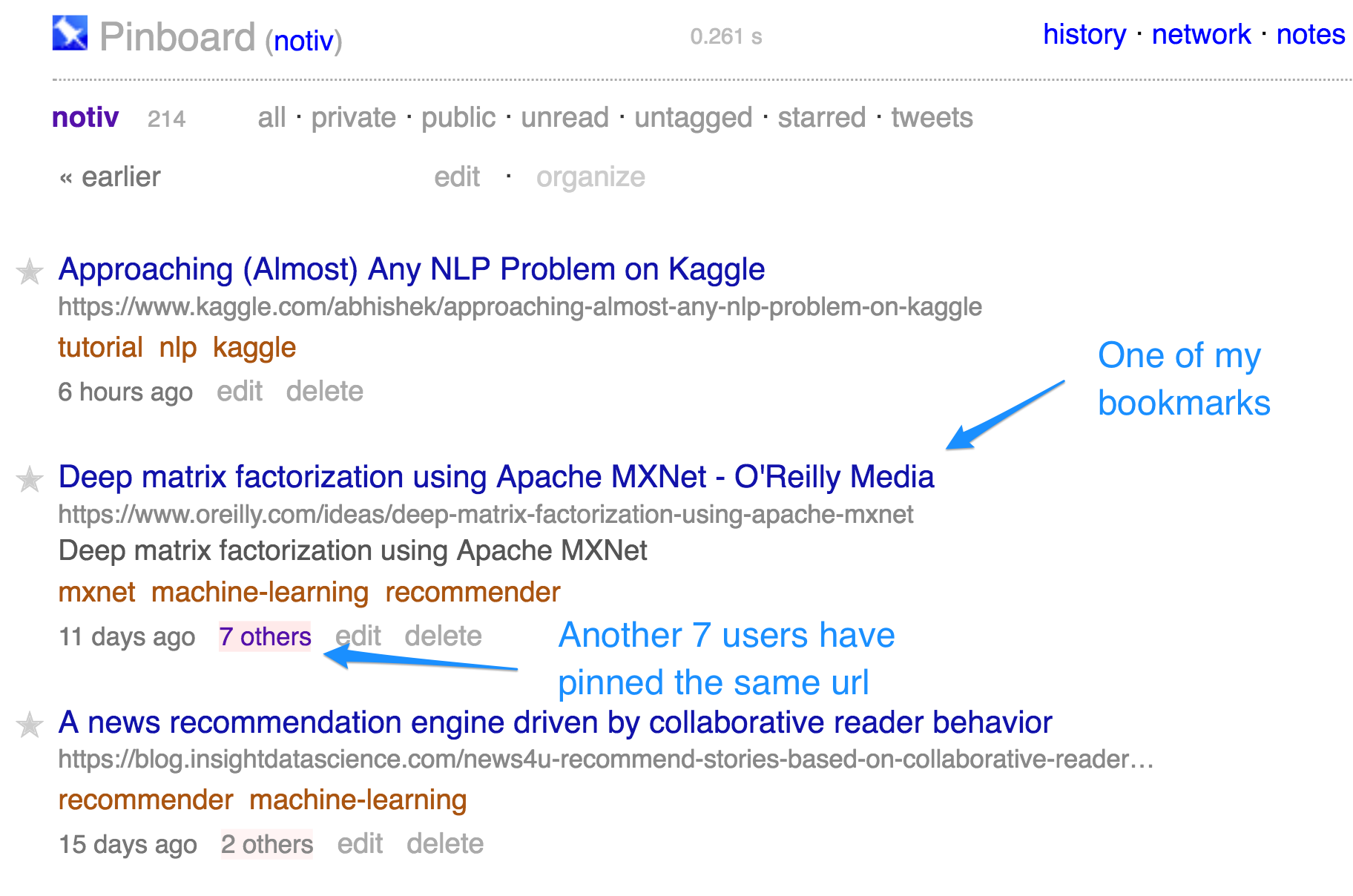
In this screenshot you can see my bookmarks as of October 28, 2017, among which a post on deep matrix factorization using MXNet. This bookmark has also been saved by another 7 users; if one clicks on the number in pink, they can see these users along with the date they saved the bookmark on and the tags they used.
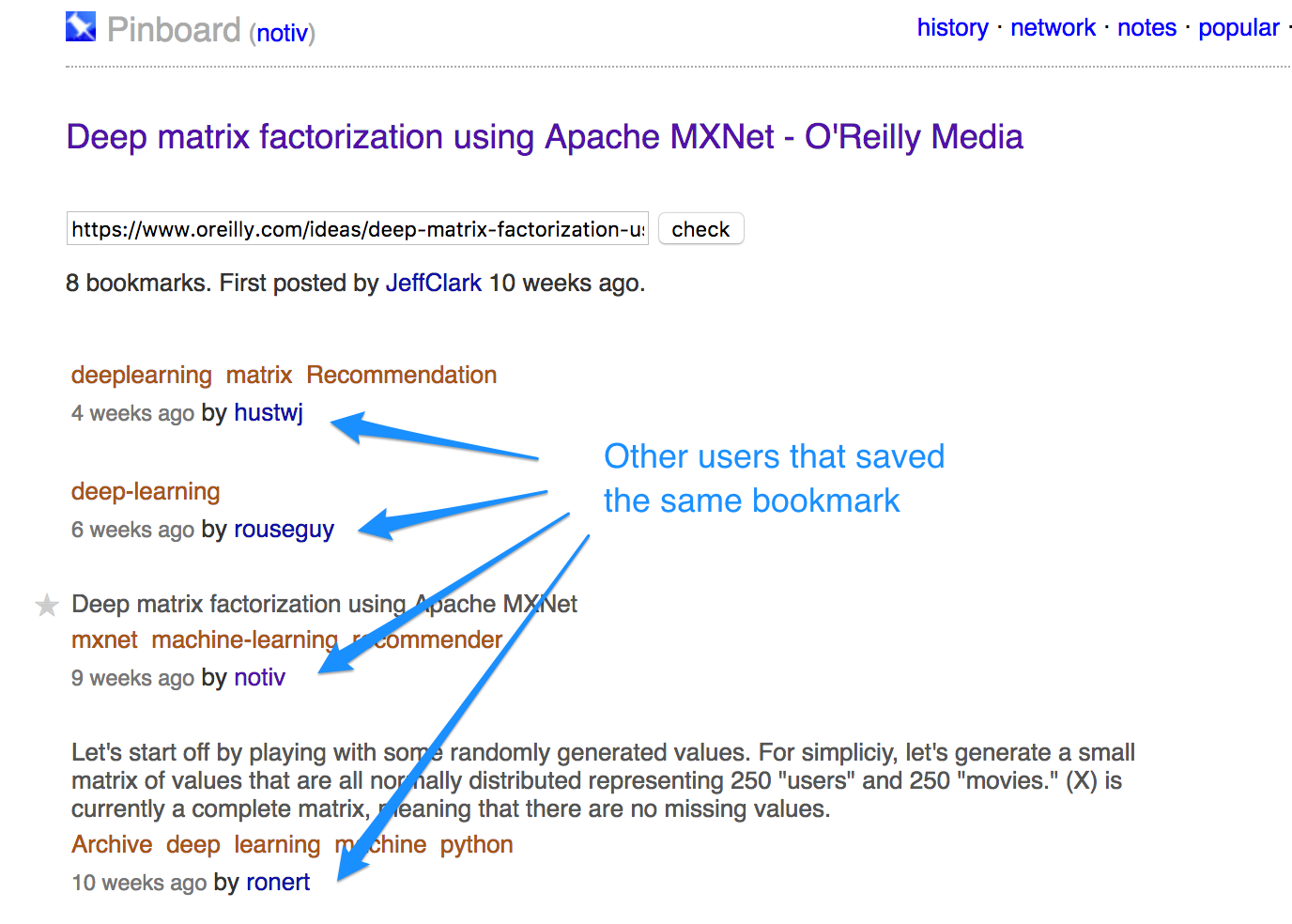
Using this structure, we can organize the parsing:
- We start with a user and scrape all the bookmarks, as seen in the first screenshot.
- For each bookmark, identified by a url_slug, we find all users that have also saved the same bookmark, as seen in the second screenshot.
- For each user from step 2, we repeat the process (go to 1, …).
Before we begin
Installing Scrapy, ideally using a virtual environment, is straightforward. After creating a project, there are a few things that we need to take care of, i.e. define the structure of the items that will be parsed, define the Spider that will do the parsing, and finally define the pipelines to store the parsed objects. Let’s check the details.
Scrapy Items
Items are simple containers used to collect the scraped data. In our case there are two types of such items, the PinItem, which contains information about a bookmark, and the UrlSlug, which contains information about other users that have pinned a bookmark. Here the corresponding classes:
import scrapy
class PinItem(scrapy.Item):
id = scrapy.Field()
url = scrapy.Field()
url_id = scrapy.Field()
url_slug = scrapy.Field()
url_count = scrapy.Field()
title = scrapy.Field()
created_at = scrapy.Field()
pin_fetch_date = scrapy.Field()
tags = scrapy.Field() # array of tags
author = scrapy.Field()class UrlSlugItem(scrapy.Item):
url_slug = scrapy.Field()
url = scrapy.Field()
user_list = scrapy.Field() # array of users who have saved this pin as well
user_list_length = scrapy.Field() # number of users who have saved this pin as well
all_tags = scrapy.Field() # array of tags from all users
url_slug_fetch_date = scrapy.Field()Spider
The spider is the class that defines how the pinboard site will be scraped, including how to perform the crawl (i.e. follow links) and how to extract structured data from the pages.
The spider needs to be initialized by providing the first URLs that will be parsed:
class PinSpider(scrapy.Spider):
name = 'pinboard'
# Before = datetime after 1970-01-01 in seconds, used to separate the bookmark pages of a user
def __init__(self, user='notiv', before='3000000000', *args, **kwargs):
super(PinSpider, self).__init__(*args, **kwargs)
self.start_urls = ['https://pinboard.in/u:%s/before:%s' % (user, before)]
self.logger.info("[PINSPIDER] Start URL: %s" % self.start_urls[0])
self.count_users = 0
self.users_parsed = {}
self.url_slugs_parsed = {}
self.before = before
self.re_url_extract = re.compile('url:(.*)')The parse method is the default callback used by Scrapy to process downloaded responses and a central piece of code in our example:
def parse(self, response):
# fetches json representation of bookmarks instead of using css or xpath
bookmarks = re.findall('bmarks\[\d+\] = (\{.*?\});', response.body.decode('utf-8'), re.DOTALL | re.MULTILINE)
self.logger.info("[PINSPIDER] Bookmarks on this page: %d" % len(bookmarks))
current_user = json.loads(bookmarks[0])['author']
user_in_dict = self.users_parsed.get(current_user)
if user_in_dict is None:
self.count_users += 1
self.users_parsed[current_user] = 1
else:
# Count pages for user
self.users_parsed[current_user] += 1
for b in bookmarks:
bookmark = json.loads(b)
if bookmark['url_slug'] in self.url_slugs_parsed:
self.logger.info("[PINSPIDER URL %s has already been parsed." % bookmark['url_slug'])
else:
yield from self.parse_bookmark(bookmark)
# Get bookmarks in previous pages
previous_page = response.css('a#top_earlier::attr(href)').extract_first()
if previous_page:
previous_page = response.urljoin(previous_page)
self.logger.info("[PINSPIDER] Fetching previous page: %s" % previous_page)
yield scrapy.Request(previous_page, callback=self.parse)def parse_bookmark(self, bookmark):
pin = PinItem()
pin['id'] = bookmark['id']
pin['url'] = bookmark['url']
pin['url_slug'] = bookmark['url_slug']
pin['url_count'] = bookmark['url_count']
pin['title'] = bookmark['title']
created_at = datetime.datetime.strptime(bookmark['created'], '%Y-%m-%d %H:%M:%S')
pin['created_at'] = created_at.isoformat()
pin['pin_fetch_date'] = datetime.datetime.utcnow().isoformat()
pin['tags'] = bookmark['tags']
pin['author'] = bookmark['author']
yield pin
yield scrapy.Request('https://pinboard.in/url:' + pin['url_slug'], callback=self.parse_url_slug)There are two things to note: First, this method yields a PinItem, i.e. it returns the parsed bookmark information. In addition, the method yields a second scrapy Request with the corresponding url slug information. The callback, parse_url_slug, is shown here:
def parse_url_slug(self, response):
url_slug = UrlSlugItem()
if response.body:
soup = BeautifulSoup(response.body, 'html.parser')
tagcloud = soup.find_all("div", id="tag_cloud")
all_tags = [element.get_text() for element in tagcloud[0].find_all(class_='tag')]
users = soup.find_all("div", class_="bookmark")
user_list = [re.findall('/u:(.*)/t:', element.a['href'], re.DOTALL) for element in users]
user_list_flat = sum(user_list, []) # Change from list of lists to list
url_slug['url_slug'] = re.findall('url:(.*)', response.url)[0]
url_slug['url'] = response.url
url_slug['user_list'] = user_list_flat
url_slug['user_list_length'] = len(user_list_flat)
url_slug['all_tags'] = all_tags
url_slug['url_slug_fetch_date'] = datetime.datetime.utcnow().isoformat()
yield url_slug
for user in user_list_flat:
if user in self.users_parsed:
self.logger.info("[PINSPIDER] User %s already parsed." % user)
else:
yield scrapy.Request('https://pinboard.in/u:%s/before:%s' % (user, self.before), callback=self.parse)Pipelines
After an item has been scraped, it is sent to one or more Pipelines, objects that perform an action on the item. Typical uses of pipelines are data cleansing or validation, duplicate removal or item storage. We implemented the latter for three interfaces, i.e. for storing the item in a file, on AWS S3 and in a MongoDB collection.
Local Pipeline
The pipeline for locally storing a scraped item differentiates between a PinItem and a UrlSlugItem and stores each one in the corresponding folder as a json file:
class PinscrapyPipeline(object):
def process_item(self, item, spider):
itm_type = item_type(item)
if itm_type == 'pin':
author = item['author']
url_slug = item['url_slug']
self.file = open('users/%s_%s_%s.jl' %(itm_type, author, url_slug), 'w')
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
self.file.close()
elif itm_type == 'urlslug':
url_slug = item['url_slug']
self.file = open('url_slugs/%s_%s.jl' %(itm_type, url_slug), 'w')
line = json.dumps(dict(item)) + "\n"
self.file.write(line)
self.file.close()
return itemAWS S3 Pipeline
The AWS S3 pipeline makes sure that an S3 bucket exists and then the same processing takes place as before:
class PinscrapyPipeLineS3(object):
def __init__(self):
self.s3client = None
self.bucket_name = None
def open_spider(self, spider):
self.s3client = boto3.client('s3')
self.bucket_name = spider.settings.get('AWS_BUCKET_NAME')
# Check that the bucket exists, otherwise create it
if not any(b['Name'] == self.bucket_name for b in self.s3client.list_buckets()['Buckets']):
self.s3client.create_bucket(Bucket=self.bucket_name)
else:
spider.logger.info('[PINSPIDER] Bucket %s exists' % self.bucket_name)
def close_spider(self, spider):
pass
def process_item(self, item, spider):
itm_type = item_type(item)
if itm_type == 'pin':
author = item['author']
url_slug = item['url_slug']
object_key = 'users/%s_%s_%s.jl' %(itm_type, author, url_slug)
object_content = json.dumps(dict(item)) + "\n"
resp = self.s3client.put_object(Bucket=self.bucket_name, Key=object_key, Body=object_content)
print(resp)
elif itm_type == 'urlslug':
url_slug = item['url_slug']
object_key = 'url_slugs/%s_%s.jl' %(itm_type, url_slug)
object_content = json.dumps(dict(item)) + "\n"
self.s3client.put_object(Bucket=self.bucket_name, Key=object_key, Body=object_content)
return itemMongoDB Pipeline
The MongoDB pipeline creates two collections -one for the PinItems, one for the UrlSlugs, and then creates a primary and, for the PinItem collection, a secondary index for quick updates and searches.
class PinscrapyMongoPipeline(object):
pin_collection_name = 'pins'
urlslug_collection_name = 'urlslugs'
def __init__(self, mongo_uri, mongo_db):
self.mongo_uri = mongo_uri
self.mongo_db = mongo_db
@classmethod
def from_crawler(cls, crawler):
return cls(
mongo_uri=crawler.settings.get('MONGO_URI'),
mongo_db=crawler.settings.get('MONGO_DATABASE', 'items')
)
def open_spider(self, spider):
self.client = pymongo.MongoClient(self.mongo_uri)
self.db = self.client[self.mongo_db]
if not self.db.get_collection(self.pin_collection_name):
self.db.create_collection(self.pin_collection_name)
if not self.db.get_collection(self.urlslug_collection_name):
self.db.create_collection(self.urlslug_collection_name)
# Create index (if none exists) to make updates faster
self.db[self.pin_collection_name].create_index([('url_slug', pymongo.ASCENDING), ('author', pymongo.ASCENDING), ('create_at', pymongo.ASCENDING)])
self.db[self.pin_collection_name].create_index([('author', pymongo.ASCENDING)])
self.db[self.urlslug_collection_name].create_index([('url_slug', pymongo.ASCENDING)])
def close_spider(self, spider):
self.client.close()
def process_item(self, item, spider):
itm_type = item_type(item)
if itm_type == 'pin':
# self.db[self.pin_collection_name].insert_one(dict(item))
# self.db[self.pin_collection_name].update({'url_slug': item['url_slug']}, {'$set': {'pin_fetch_date': item['pin_fetch_date']}}, upsert = True)
self.db[self.pin_collection_name].update({'url_slug': item['url_slug']}, dict(item), upsert=True)
elif itm_type == 'urlslug':
self.db[self.urlslug_collection_name].update({'url_slug': item['url_slug']}, dict(item), upsert=True)
return itemFinal Notes
The spider can be improved in a number of ways. First of all, it does not perform any particular testing nor does it guarantee that all pins or url slugs in the parsing queue are indeed scraped. Moreover duplicate detection could be performed in a more active manner, particularly in the case of the MongoDB pipeline, where we can track what has already been inserted. The logs could be stored in a database or, preferably, in ElasticSearch to enable efficient analysis of warnings and errors. Finally, we haven’t mentioned anything about the settings we used for scraping. Concurrency has been set to 1 and the download delay has been set to 2 seconds in order to be nice to the site. If you use the code here, I would strongly encourage you to do the same. Thanks :-)